

Angels in the Architecture (interlude pt iii)
Angels in the Architecture (interlude pt iii)
On the limits of 3M's Visual Attention Software in architectural research

[One last interlude in a too-long series of too-long posts with a lot of images. Read the first installment here. Consider clicking over to the Substack site if the images won’t load fully in your inbox.]

Previous installments of this series have looked at how small, non-architectural changes to input imagery—things like lighting or camera position—can significantly impact the outputs generated by 3M’s VAS tool. These small changes are the sort of thing we introduce constantly in the day-to-day practice of working with images of buildings: site visits on different days may have different weather conditions or qualities of light. Different rendering engines will represent the same space slightly differently. And so on. That VAS can be so disrupted by these types of changes is concerning.
What if we make changes that aren’t just incidental but instead are actively adversarial? Can we “fool” VAS by feeding it manipulated input imagery to give us the sort of results we want to see?
Below are two images, one from Twitter and one from a construction company website. I’ve resized and slightly cropped the image of the Caltrans District 7 building. The image of Paris is untouched. Both are 1920x1080px JPEGs.


Running each of these through VAS gives us the two heatmaps below. We’ll be coming back to these shortly.

Misting and Glazing
I’m not aware of any tools designed specifically to disrupt VAS but someday such a tool could exist. In other domains, people are already exploring means of disrupting AI image processing.
Mist and Glaze are two independent tools designed for visual artists to add an ‘invisible’ layer of protection to their work before sharing it online. This protective layer modifies the image ever-so-slightly in ways that are intended to be imperceptible for human viewers but very perceptible for AI image models like Midjourney which are trained on existing artworks.
From Glaze:
“Human eyes might find a glazed charcoal portrait with a realism style to be unchanged, but an AI model might see the glazed version as a modern abstract style, a la Jackson Pollock. So when someone then prompts the model to generate art mimicking the charcoal artist, they will get something quite different from what they expected.”
and from Mist:
By adding watermarks to the images, Mist renders them unrecognizable and inimitable for the models employed by AI-for-Art applications. Attempts by AI-for-Art applications to mimic these Misted images will be ineffective, and the output image of such mimicry will be scrambled and unusable as artwork.
My hunch is that these tools will not “defeat” VAS—whatever that would look like—but that they will confuse it to some degree. Compared to the unaltered images above, the VAS heatmaps produced from these Misted and Glazed images should look a bit unusual. Let’s take a look.
I took the base images above and processed each through the Glaze and Mist tools to generate new inputs (left column below), then ran the resulting images through VAS (right column below).
Glaze and Mist have slightly different controls and settings, ranging from the most conservative (edits are less perceptible but the output effect on AI tools is less powerful) to the most aggressive (more powerful but more noticeable). For the images below, the settings used were in the middle: neither too conservative nor too aggressive.1
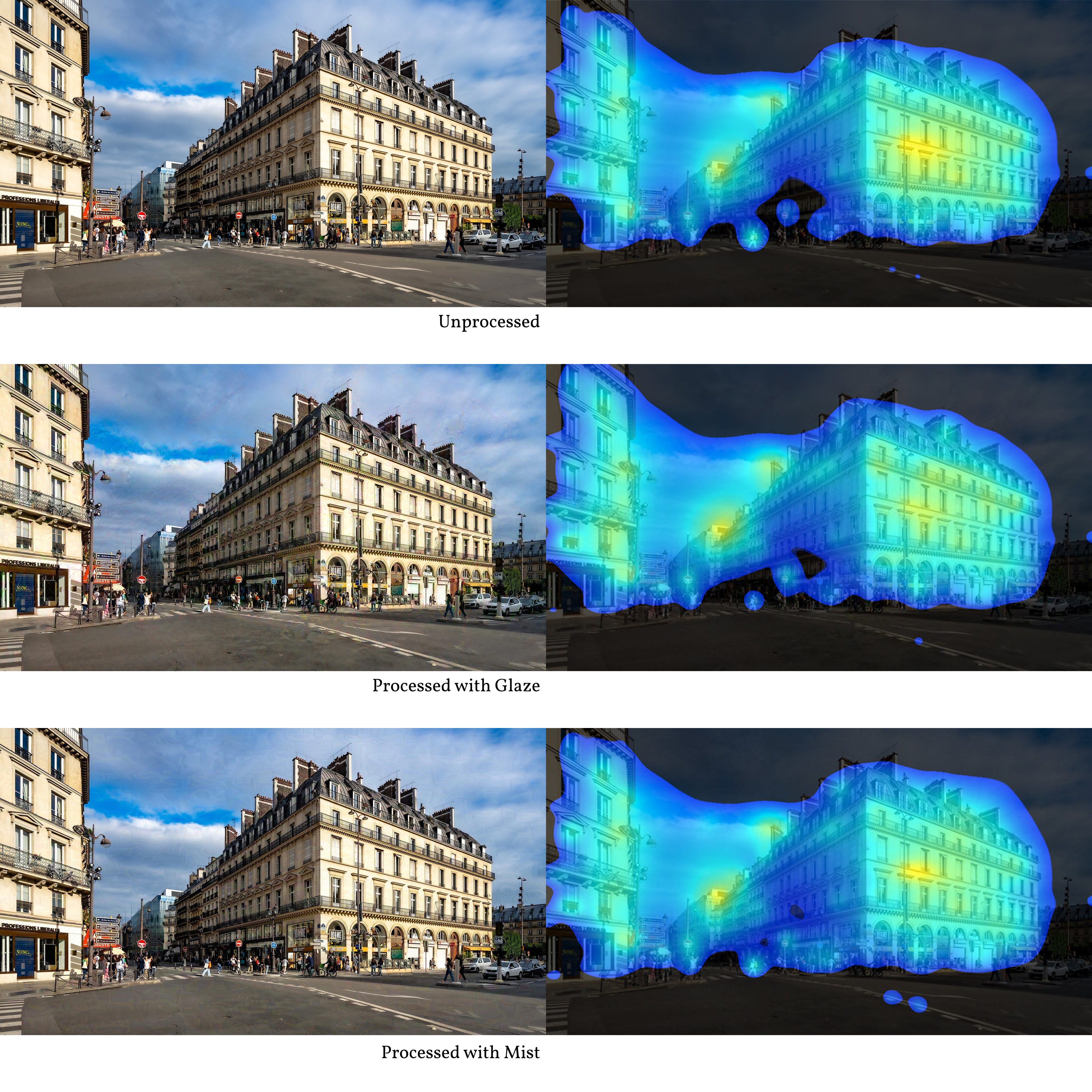
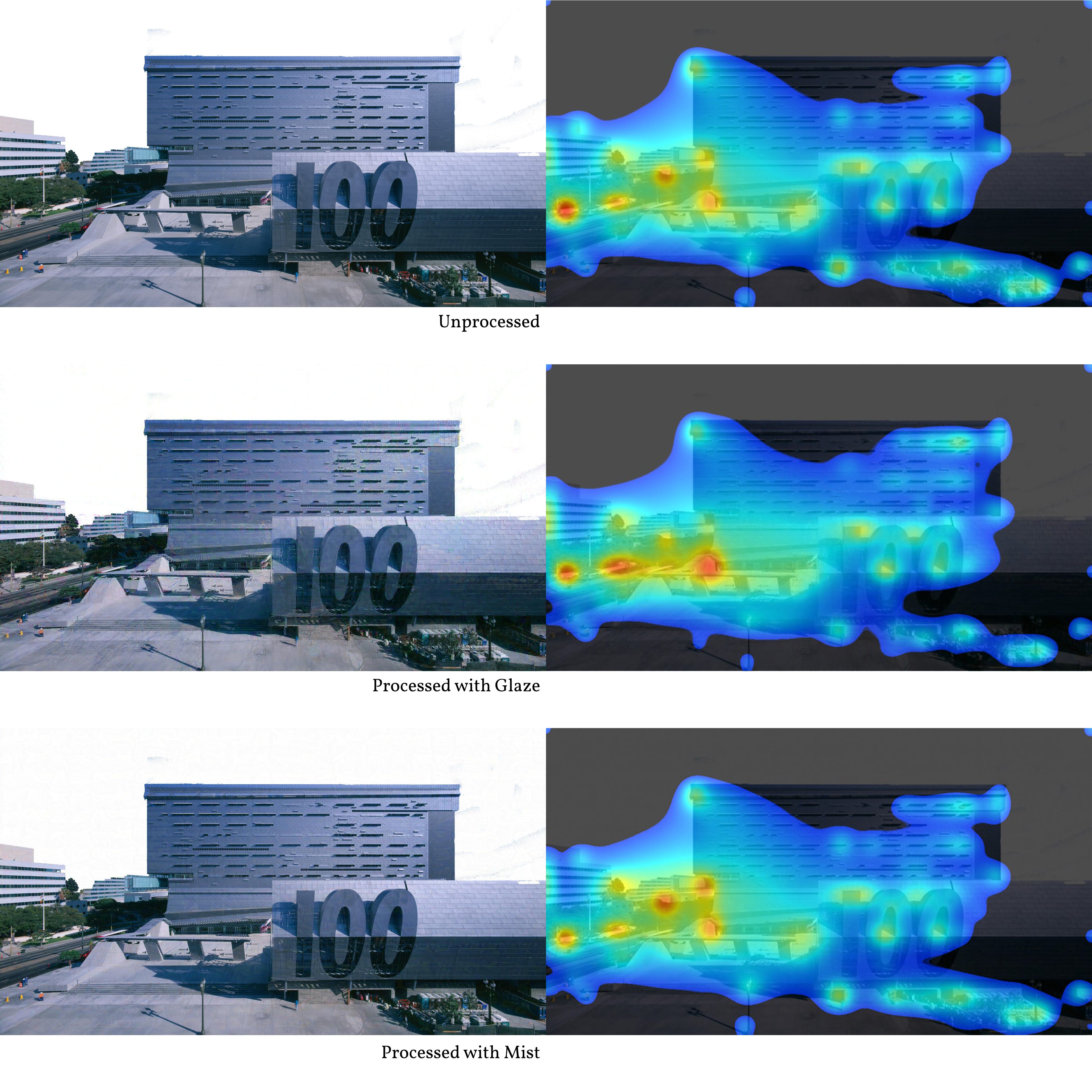
More visible on zooming in, Glaze and Mist have each produced some noise/artifact around the input images. A keen observer on the lookout for manipulation would surely spot it, but someone reviewing many images at once might not. The VAS outputs show some minor differences in how the inputs are interpreted. A void in the center of the Parisian streetscape heatmap is almost entirely filled in the Misted version. Likewise, the Glazed version of the Caltrans building produces a heatmap with more coverage across the main facade.
Quick Cheap Exploit
Here’s a way to use Glaze and Mist to “improve” the VAS results for a particular building without having to change the building at all. When that lovely photo of a Parisian streetscape was first posted the caption inspired some discussion about the…uh…largesse of U.S. developers re: quality of new developments, nicely illustrated by Twitter user @brianonhere.

Here’s what that modification looks like compared to the original, along with the VAS heatmap for both.

Let’s suppose an unscrupulous builder wanted to use VAS to make some scientific-sounding claims about a proposed facade while also slashing the budget and delivering a worse final product. Could they somehow combine the two images above to eliminate the voids that occur in the center of each? Yes, they could.
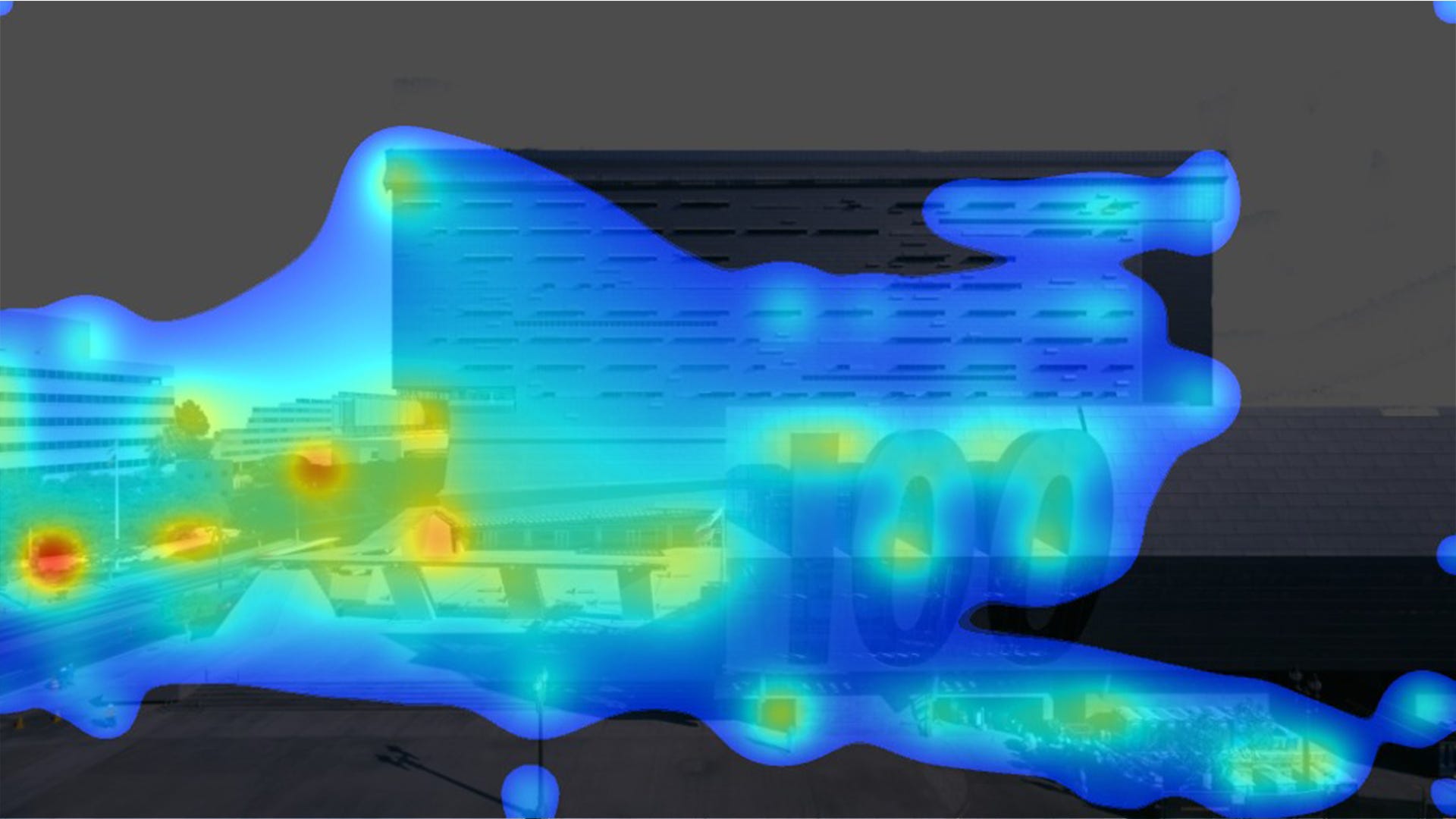
Using Photoshop blending modes, it was easy to combine the Glazed and Misted versions of the Paris streetscape and then extract the pixels that differed from the unprocessed image. Below is part of what that looks like, with 100% white pixels indicating no difference between the input and the output.

This sort of thing is, I assume, where Glaze and Mist get their names. Notice how the most prominent pixels still trace out the underlying contours of the buildings in our source image. VAS should be able to pick up on this too.
And it does. The top row below is just our regular input image and its corresponding heatmap. Below, I’ve overlaid that white Glaze/Mist image extracted from the Paris photo. When VAS analyzes this new version, it “sees” information from the Glaze/Mist layer and produces a different heatmap. That big void in the middle has been reduced to something the size of a single window.

This is more napkin-sketch than sophisticated effort to deceive VAS. Tools could be developed to flag this sort of manipulation, which would almost surely inspire new tools to get around flags and detection.
We already bemoan overly rosy or manipulative renderings. These complaints generally don’t include the idea that additional patterns have been layered in for subliminal influence. An overconfidence in VAS risks opening a door to a world where that sort of behavior is commonplace.
This is the penultimate post in this series. One final conclusion to tie things together coming to your inbox soon. Thanks for being here.
:-)
Vitruvius Grind
PS: Did you notice anything different about the Wile E. Coyote cover image on this one? The center bit (the School of Athens part) has been processed through Mist. If you aren’t primed to look for it it can escape notice.
I have unfortunately misplaced the exact numerical values I used for the inputs, but if you are trying to replicate any of this work please get in touch and I’ll be more than happy to share any information and resources I can.